基于DSP的语音识别系统设计毕业论文
2020-04-22 19:37:12
摘 要
近年来,随着语音识别研究的深入,语音识别系统已经融入实际应用。语音识别系统通过提过自动化服务来改善人机交互环境,这使大众的的生活得到便利。在残疾人救助方面,语音识别系统能帮助一些读写障碍的残疾人士表达信息。
本文设计了一种基于孤立词的小词汇量语音识别系统,该系统可以对特定人的孤立词0到9进行语音识别。系统设计分为两个部分:首先,仿真部分在MATLAB平台上进行语音识别系统仿真,测试语音参数提取,匹配算法的可行性。其次,硬件实现部分在数字信号处理器(Digital Signal Processing,DSP)平台上设计语音识别系统,系统能完成语音的采集并对其进行处理,最后识别处语音信息。
设计基于MATLAB搭建了一个孤立词语音识别系统,该系统完成了语音信号的预处理,梅尔参数提取(Mel Frequency Cepstral Coefficients,MFCC)和模板匹配的算法验证。设计中对语音处理过程的一些理论仿真结果进行了对比分析。在DSP平台上完成了基于动态时间规整(Dynamic Time Wrapping,DTW)的语音参数匹配,测试语音能正确匹配参考模板中的语音参数。
关键字:孤立词、语音识别、MFCC、DTW
Abstract
In recent years, with the deepening of speech recognition research, speech recognition system has been integrated into practical applications.Speech recognition systems improve human-computer interaction by providing automated services that make life easier for the masses.In terms of disability assistance, speech recognition systems can help some people with dyslexia express information.
This paper designs a small vocabulary speech recognition system based on isolated words, which can recognize isolated words from 0 to 9.The system design is divided into two parts: first, the simulation part carries on the speech recognition system simulation on the MATLAB platform, tests the speech parameter extraction, and the feasibility of the matching algorithm.Secondly, the hardware implementation part designs the speech recognition system on the platform of Digital Signal Processing (DSP), which can complete the speech acquisition and Processing, and finally identify the speech information.
A speech recognition system of isolated words is designed and constructed based on MATLAB. This system completes the preprocessing of speech signals, Mel Frequency Cepstral Coefficients (MFCC) extraction and algorithm validation of template matching.Some simulation results of speech processing are compared and analyzed.Speech parameter matching based on Dynamic Time Wrapping is completed on DSP platform, and the tested speech can correctly match the speech parameters in the reference template.
Keywords: isolated words, speech recognition, MFCC, DTW
目录
摘要 I
Abstract II
第一章 绪论 4
1.1语音识别研究背景 4
1.2语音识别面临的问题 5
1.3论文的研究内容 5
1.4本章小结 6
第二章 语音识别流程和算法 7
2.1语音识别系统框架 7
2.2语音预处理 7
2.2.1语音采集 7
2.2.2短时语音处理 8
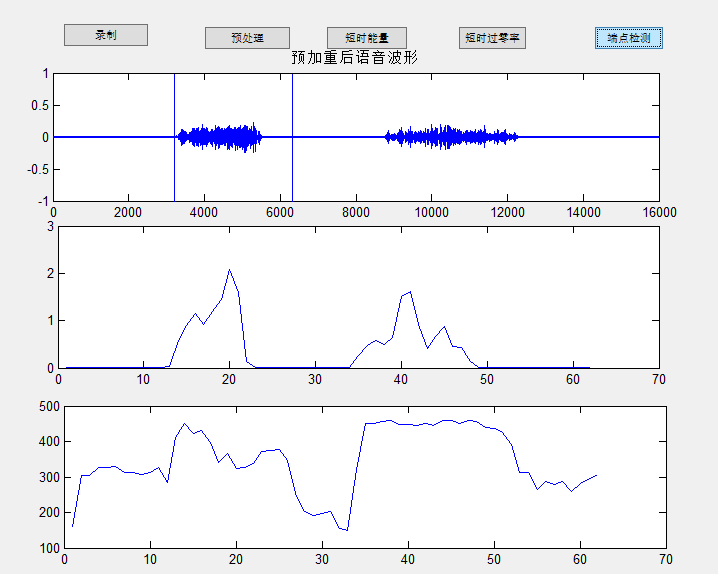
2.2.3语音端点检测(vad) 9
2.3语音参数提取 11
2.3.1语音特性 12
2.3.2线性预测编码(Linear Predictive Coding,LPC) 12
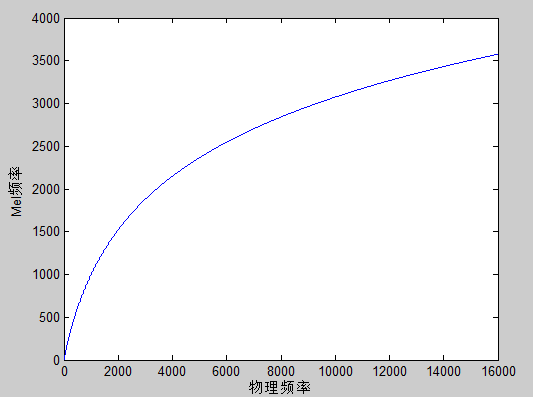
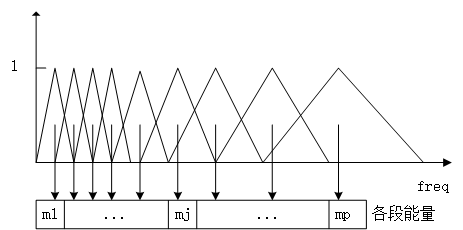
2.3.3梅尔倒谱系数 13
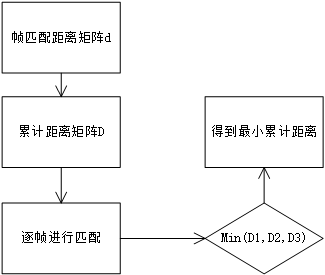
2.4模板匹配 16
2.4.1匹配算法理论 17
2.4.2匹配算法设计 20
2.5本章小结 20
第三章 语音识别系统MATLAB仿真 21
3.1语音端点检测 21
3.2梅尔特征参数的提取 23
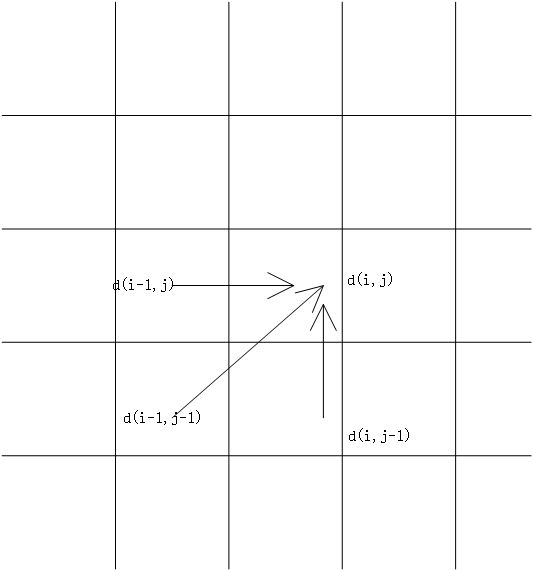
3.3动态时间规整 24
3.4 图形用户界面(GUI)设计介绍 25
3.4.1端点检测的GUI设计 25
3.4.2系统整体GUI设计 25
3.5系统整体仿真 26
3.6本章小结 27
第四章 DSP设计语音识别系统 28
4.1硬件电路设计 28
4.1.1系统时钟设计 29
4.1.2音频录入设计 29
4.1.3外扩SRAM设计 32
4.2系统软件设计 34
4.2.1 实时语音端点检测 35
4.2.2 FFT算法的仿真 36
4.2.3 DTW算法 37
4.3本章小结 37
第五章 总结和展望 38
参考文献 39
致谢 40
第一章 绪论
语音识别系统研究从20世纪初期开始,经过了近百年的发展,现在已经应用到大众的日常生活中。本章对语音识别的背景,发展过程中的重要节点和语音识别的技术难点做了介绍。
1.1语音识别研究背景
自动语音识别(ASR)是一个综合性的研究领域。系统开发涉及到声学,计算机科学,数字信号处理,语音编解码等研究领域。其中有几个关键的问题:如何表示信号,如何对语音参数进行建模,如何寻找合适的最优解匹配。
语音波形不能直接用于解决语音识别问题。系统设计时,前端对语音进行预处理,并将其转换为一系列特征向量作为语音参数。这些语音参数作为匹配样本被输入到后端处理。在后端处理中,先创建匹配模板,然后将测试语音和模板进行匹配,经过匹配后最相似的模板被认为是识别输出。因此语音识别的主要步骤可概括为:语音采集、特征提取、模式匹配。整个设计流程中最重要的是完成模式匹配。可靠的距离匹配函数和输入语音的参数提取是语音识别算法的关键,本设计主要研究语音识别的模板匹配问题。设计中选用DTW作为模板匹配方法。
相关图片展示: