与文本相关的说话人识别系统设计毕业论文
2020-04-22 19:35:23
摘 要
传统的身份认证方法,例如使用ID卡,密码,密钥等,不方便且易于伪造或易受攻击,导致安全性和可靠性差[1]。声纹因其独特的便利性、经济性和准确性而吸引人类眼球,声纹识别技术已经越来越成熟,成为人们日常生活和工作中一种重要的安全认证方法。
本文设计的与文本相关的声纹识别系统是通过输入相同的语音来测试说话人的身份是否正确。因为机器不能直接识别输入的语音,所以要先进行预处理,对信号进行采样,因为语音信号的短时稳定性,对其加窗分帧,最后是端点检测,目的是有效地提高识别性能和节省检测时间。然后是特征参数提取和建立识别模型,根据声纹识别系统的研究现状,本文对已有的方法进行简要分析并选择最适合本设计方案。本设计在识别方法中,结合Mel频率倒谱系数的提取,利用矢量量化压缩特征参数,得到说话人发音的码本。最后输入待测语音,比较其特征参数与码本库之间的欧氏距离。本文通过实验仿真,对说话人身份测试识别率较高。
关键词:声纹识别 预处理 Mel频率倒谱系数 矢量量化
Text-based Voiceprint Recognition System
Abstract
Traditional methods of identifying, such as using ID cards, passwords, keys, etc.[2], are inconvenient, easy to forge or vulnerable to attack, resulting in poor security and reliability. Using sound to identify attracts human’s eyeball because of its unique convenience, economy and accuracy, and it has become more and more mature, and widely used as authentication method among people's daily life and work.
The text-related acoustic recognition system designed in this paper tests whether the speaker's identity is correct by entering the same speech. Because the machine can not directly recognize the input voice, so the first preprocessing, the signal sampling, because of the short-time stability of the speech signal, the window is divided into frames, and finally the endpoint detection, the purpose is to effectively improve the recognition performance and save detection time. Then there is the feature parameter extraction and the establishment of the recognition model, according to the research status of the sound pattern recognition system, this paper makes a brief analysis of the existing methods and selects the most suitable for this design scheme. In the identification method, combined with the extraction of Mel frequency inversion coefficient, this design uses vector quantization to compress the characteristic parameters to obtain the codebook pronunciation of the speaker. Finally, the speech to be measured is entered, and the Euclidean distance between its characteristic parameters and the code library is compared. In this paper, the recognition rate of speaker identity test is high through experimental simulation.
Key Words: Voiceprint Recognition; preprocessing; MFCC; Vector Quantization
目 录
目录
摘 要 I
Abstract II
第一章 绪论 1
1.1 课题相关背景及意义 1
1.2声纹识别技术发展现状及特点 1
1.3 声纹识别技术发展前景 3
1.4 论文的主要内容介绍 4
第二章 相关技术的介绍 5
2.1 声纹识别简介 5
2.1.1 声纹识别的类型 5
2.1.2 声纹识别系统的基本原理 6
2.2语音预处理方法及方案分析 7
2.2.1 语音的采样 7
2.2.2 预加重处理 7
2.2.3 加窗和分帧 7
2.2.4 端点检测 8
2.3主要识别模型分析 10
2.3.1模板匹配法 11
2.3.2矢量量化 11
2.3.3 高斯混合模型 13
2.3.4 人工神经网络法 14
2.4 本章小结 14
第三章 语音特征参数提取 15
3.1 线性预测倒谱系数LPCC 15
3.2 梅尔频率倒谱系数MFCC 15
3.2.1 倒谱分析 15
3.2.2 Mel频率分析 16
3.2.3 Mel频率倒谱系数 16
3.3 本章小结 17
第四章 声纹识别系统的软件实现 18
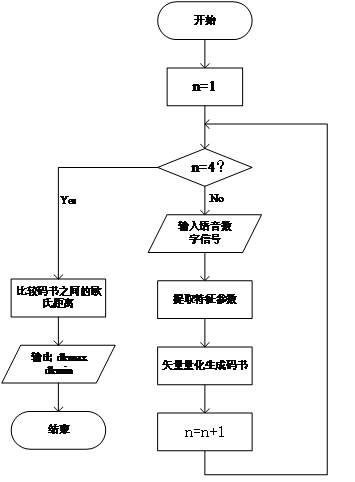
4.1 程序流程实现 18
4.1.1 设置四个按钮 18
4.1.2特征参数提取过程分析 19
4.1.3 矢量量化 22
4.2 本章小结 22
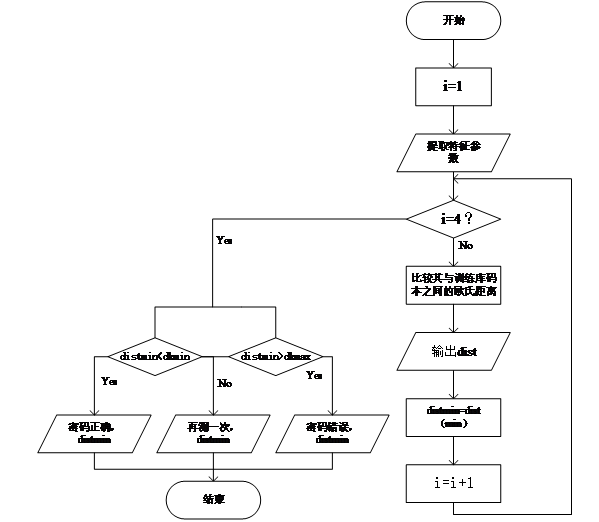
第五章 语音测试过程 23
4.1 测试结果 23
4.2 问题反思 25
4.3 本章小结 25
结 语 26
参考文献 27
致 谢 28
第一章 绪论
1.1选题背景及意义
现有的身份认证技术因容易泄漏或遗忘存在很大弊端,难以满足长期安全和高安全性的要求。语言是人类的自然属性之一,既不会丢失也不会被遗忘,加上说话者自身的生理特征及后天形成的音色的不同,每个人的声音和声纹信息都是独一无二的。此外,易于获取语音信号和系统设备成本低的优点为声纹识别技术提供了广阔的应用前景[3]。
根据说话人用于训练和测试的语音文本,说话人识别可分为两类:与文本相关和与文本无关。前者识别过程中因建立模型需要的语音数据量大,而且单纯依靠说话人声纹信息的方式识别率较低,且存在说话人语音被窃取录制、被模仿等风险,在高安全性能的要求的情况下,很难单独使用这项技术进行声纹识别。而后者与文本相关的说话人识别要求训练和识别的时候使用内容相同的语音文本,只需要采用较少的训练和测试语音数据就能够达到较高的识别率,同时测试的语音文本内容本身也是识别过程中一项重要的判定信息,相同文本的语音几乎是不可能被窃取录制,在文本未知的情况下也不能被模仿,安全性能很高,具有很大的实际意义及研究价值。
1.2声纹识别技术发展现状及特点
相关图片展示: